PC98 for ZAURUS には PC-9801 の BIOS ROM 相当のシステムが内蔵されているので、実機から BIOS ROM を吸い出さなくても動きますが、フォントファイルだけは別途用意しなければなりません。本来ならば、これも実機から吸い出す必要があるのですが、フォントファイルなんて、所詮ただの文字パターンが格納されたファイルです。プログラムじゃないんですから、フリーのフォントから変換できないかと思って、色々と試してみました。
まずはフォントファイルってのが、どんなモンなのか判らなければ変換のしようがないので、フォントファイルの中身を覗くプログラムをちょいと作ってみます。
#include <stdio.h>
main() {
int i;
long s;
char buf[1];
FILE *fp;
fp=fopen("font.rom","rb");
s=0;
while(fread(buf,1,1,fp)==1) {
printf("%08x %02x ",s,buf[0]);
i=0x80;
while(i>0) {
if((buf[0]&i)!=0) printf("XX");
else printf(" ");
}
printf("\n");
s++;
}
fclose(fp);
}
今、思い出しながら書いたのでウソがあるかも知れません(汗)でも、こんなの作って font.rom の中身を覗いてみました。早い話が先頭から1バイトずつ読み込んで、2進数で表示するものです。ただし、1の部分を「XX」、0の部分を「 」で表示することで、フォントパターンをそのまま見えるようにしています。
先ほどのプログラムで見た結果、先頭から 8×8 ドットの半角フォントが 256 文字分、8×16 ドットの半角フォントが 256 文字分、16×16 ドットの全角フォントが続けて格納されていました。下記は 8×8 ドットのフォントの例です。
00000208 00 00000209 18 XXXX 0000020a 24 XX XX 0000020b 42 XX XX 0000020c 7e XXXXXXXXXXXX 0000020d 42 XX XX 0000020e 42 XX XX 0000020f 42 XX XX
8×8 ドットの半角フォントは 8 バイトで 1 文字分、8×16 ドットの半角フォントは 16 バイトで 1 文字分、16×16 ドットの全角フォントは 32 バイトで 1 文字分です。
16×16 ドットの場合は左半分の 8×16 ドットの分の 8 バイトの次に、右半分の 8×16 ドットの分の 8バイトが続きます。
16×16ドットフォントは JIS 漢字コードの順番に並んでますが、実際の JIS 漢字コードとは少々違います。
JIS 漢字コードは 2 バイトで表される文字コードで、1 バイト目(上位バイト)が 21~7E、2 バイト目(下位バイト)が 21~7E の、2121~7E7E なんですが、この font.rom では 1 バイト目が 21~7C、2 バイト目が 20~7F の 2120~7C7F となっています。
ただし、JIS 漢字コードにおける 2 バイト目が 20 や 7F の場合は空白の文字パターンが格納されています。
参考までに X1turbo for ZAURUS で使われている font8x8.bin は、PC98 for ZAURUS の font.rom における最初の 2048 バイトと全く同様の構造になっています。つまり、8×8 ドットのフォントが 8 バイトで 1 文字分となり、0~255 の文字コード順に格納されています。
使えそうなフリーのフォントファイルと考えて思い浮かぶのは、X Window System のフォントファイルである BDF ファイル、あとは DOS/V で使われている FONTX 形式のフォントファイル、HP95LX、200LX などで有名な恵梨沙フォント、PC-E500 のために作られた美咲フォント、X680x0 で使われる Turbo Console、HFONT、HIOCS.X 用のフォントファイルがありますが、8×16、16×16 のフォントが揃っていた東雲フォントの BDF ファイルを利用することにしました。
いいじま☆だいさんのページにてフォント関連のツールがソース付で色々ありましたので、その中の bdf2fontx を見てみました。
とりあえず、いいかげんに理解したのは最初に BDF ファイルのヘッダー部が ENDPROPERTIES が出てくるまで続き、この中に FONT で始まるパラメータ行があって、フォントの名前、幅、高さ、半角/全角などが書いてある。そして、ENDPROPERTIES でヘッダー部が終わったあとにはフォントパターンのデータがあり、ENCODING 行では文字コードが示され、続いて BITMAP が現れた直後から 16 進数で 1 ライン分のフォントパターンが 1 行ずつ続いて、ENDCHAR で終わるといったカンジです。
font.rom には 8×8、8×16、16×16 の3つのフォントパターンが格納されているので、これを別々に作成して、あとで結合することにします。先頭の 2048 バイト(8×256)は 8×8、次の 4096 バイト(16×256)は 8×16、最後の 282624 バイト(32×92×96)は 16×16 のフォントデータです。
8×16 ドット半角フォントの BDF ファイルを用意して、これを font.rom の 4096 バイトに当たる部分に変換します。
#include <stdio.h>
#include <string.h>
int main(int argc,char **argv) {
int c,d,k,i;
char s[1024];
k=0;
while(gets(s)!=NULL) {
if(strncmp(s,"ENCODING ",9)==0) {
sscanf(s,"ENCODING %d",&c);
if(c>0xff) break;
while(c>k) {
for(i=0;i<16;i++) putchar(0);
k++;
}
}
if(strcmp(s,"BITMAP")==0) {
i=0;
while(gets(s)!=NULL) {
if(strcmp(s,"ENDCHAR")==0) break;
sscanf(s,"%x",&d);
putchar(d);
}
k++;
}
}
while(k<=0xff) {
for(i=0;i<16;i++) putchar(0);
k++;
}
}
標準入力から BDF ファイルを 1 行ずつ読んで、ENDCODING 行が出現したら、文字コードを控えておき、BITMAP 行が出現したら、ENDCHAR が出るまでの間を 1 バイトのバイナリデータとして標準出力に吐き出します。これを繰り返して変換する訳です。
ただし、文字コードが抜けなく順番に出てくるとは限らないので、文字コードが急に大きくなったら、間の文字コードの分は空白の文字パターン( 0 で 16 バイト分)を出力します。
BDF ファイルでは 1 ラインが 16 ビットのデータ(1 行の 16 進数のデータ)であらわされるのに対して、font.rom では左半分の後、右半分を 8×16 ドットと同じように出力するので、16 バイトのバッファを用意して、最初に上位 8 ビット分を出力しつつ、バッファに溜め込み、同じ数だけバッファから下位 8 ビット分を出力します。
BDF ファイルにおいて、8×8 ドットの半角フォントはあまり無いので、8×16 ドットフォントから作成することにします。早い話が、8 ビットのデータを 2 つ分(2 行の16 進数のデータ)を読んで、それらを OR で重ね合わせて出力することで、フォントを圧縮しています。
こうして作ったそれぞれのプログラム(mkfnt)と、変換するフォント(東雲フォント)を用意して、以下のように変換した後に結合します。
$ mkfnt0808 < shnm8x16r.bdf > font0808.rom $ mkfnt0816 < shnm8x16r.bdf > font0816.rom $ mkfnt1616 < shnmk16.bdf > font1616.rom $ cat font0808.rom font0816.rom font1616.rom > font.rom
これで PC98 for ZAURUS で利用できるフォントファイル font.rom が作成できました。尚、font0808.rom は font8x8.bin とりネームすることで、X1turbo for ZAURUS で利用できます。
PC98 for ZAURUS
実際に PC98 for ZAURUS で使ってみた画面です。
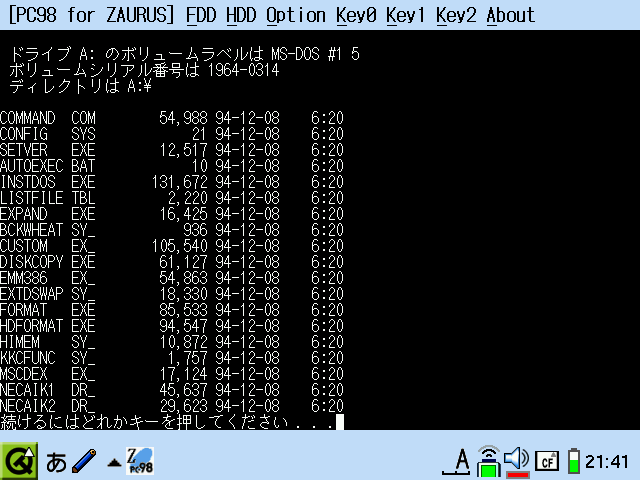
PC-9801 には独自のフォントがいくつかあるので、リターンキーなどの記号が表示されていません。
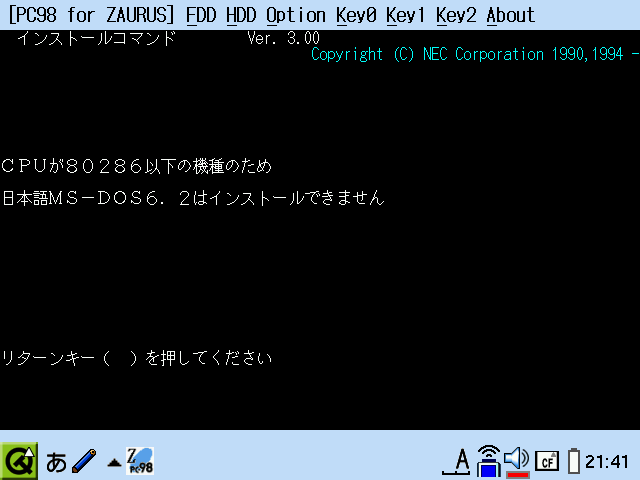
このあたりの独自フォントは別途なんとかしてみたいです。
実際に X1turbo for ZAURUS で使ってみた画面です。
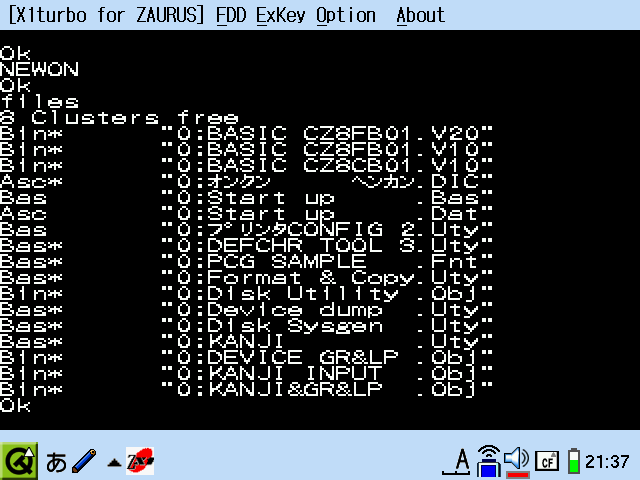
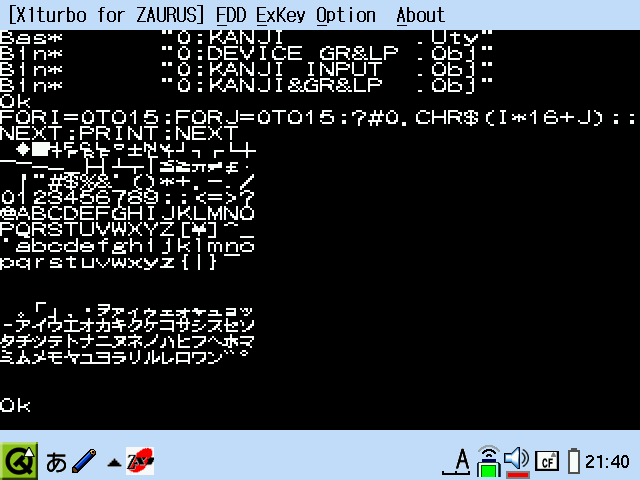
X1 にも半角フォントには独自のフォントがいくつかあるので、BASIC 起動時の枠が表示されていません。
このあたりの独自フォントは PC-9801 同様になんとかしてみたいです。