暫定おぼえがき版
辞書ファイルの本体は /home/QtPalmtop/dic/ 以下、*.gdn と *.zj_info 。
infoファイルを覗いてみると、xml/html をベースにしてるくさい。
infoファイルの中身に、漢字源の文字が見えるので、それがベースのようだ。
と、言うことで漢字源の方から、データ構造を解析する取っ掛かりが見つからないかどうか検索してみたところ、色々と発見。
学研の辞書は旧 MI ザウルス他、Palm 等でも供給されている。
→そっち系のフリーソフトのソース等が、解析の助けにならないか?
Windows ベースの学研辞書データベースの共通検索エンジンとして、GDBase なるものが公開されている。辞スパなどもこの系列。
その他の情報として、XML ベースの電子書籍の共通フォーマットと言うものが存在するらしい。
関係URL→http://ascii24.com/news/i/serv/article/1999/07/22/603541-000.html
XML ベースと言うことで、C760 の辞書もこのファイルフォーマットをベースにしている可能性はあるかも。
でも、漢字源で検索すると、EPWING の情報もひっかかる。EPWING 形式なのだとすると、既にりなざうには ZTEN が存在するんで、本末転倒(爆)
とりあえず、今度 ZTEN インストールして試してみよう。←結局試さなんだ(笑)
と、言うことで同じ学研の辞書なら、もしかしてと思ったんで、WINDOWS 用の学研の辞書を一つ購入して試してみた。
いちおう、英和・和英・国語はあるけど、漢和辞典は無いんで、これなら潰しが効くかと。
もひとつは、この辞書、実売 2000 円ちょいなんで、これくらいならダメモトで出せる金額かと(苦笑)
まずは順当にPCにインストール。
インストール先のフォルダ直下に dic/kanjigen/ で実データが入っている。
さらに、語源や拡大表示用の画像ファイル群が、同フォルダ下(dic/kanjigen/jpg)に一緒に入ってるんで、これもまとめてメモリカードにコピー。
PC にインストールしなくても、CD-ROM の /Gakken/GDBase/Dic/KANJIGEN に同じものが入っているので、これをコピーして使っても良いと思う。
この時点で、一旦 SL-C760 に持ってって、辞書の追加を試してみるが、このままではまだ辞書の追加不能。
多分、infoファイルが必要なんだろうなーと思うんで、/usr/QtPalmtop.rom/dic から、てけとーな info ファイルをコピー。
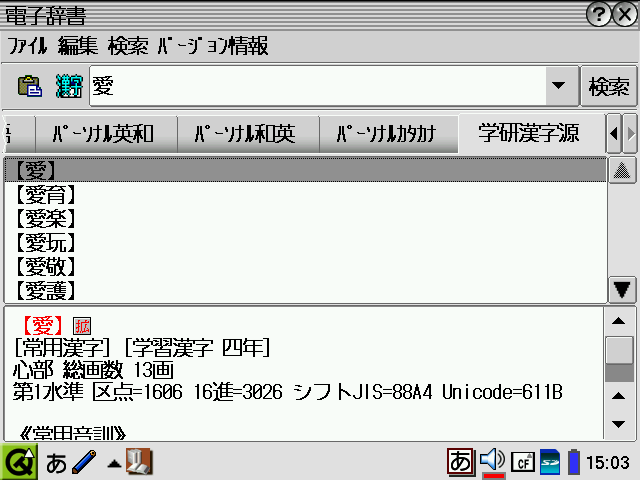
info ファイル中の、辞書名を「学研 漢字源」に。
同ファイル中で辞書ファイル本体を指示している項目があるので、kanjigen.gdn に書き替える。都合二箇所。
で、一応ファイル名を辞書ファイルに合わせてリネーム。
ここまでしたところで、もっぺん辞書の追加をさせてみると・・・おっけー。
項目中の「図」や「拡」と言ったアイコンも表示され、アイコンをタップするとちゃんと図版が表示される。ちょっとびっくり。
★その後、よくよく使ってみると、文字の拡大表示「拡」はちゃんと表示されるが、図版を表示する「図」はちゃんと機能していないことが判明。
一応、アイコン押すと反応はするんだけど・・・リンク先の JPEG 画像の表示が出来ない or リンクが切れているようだ。
と、言うことで、とりあえずりなざうで使ってる辞書が、学研辞書共通の GDBase のフォーマットに則ったものであることは確認でけた。
とりあえず、今日はここまで。
つか、なんか体調悪くて、集中出来ないんで、ちゃんとした info ファイルの解析内容とか、手順のまとめとかは、また次回。
つか、ここまで自分で書いてるのはただのメモ書きテキストで、html にすらしてまへん。
この文章が WEB に上がってるとしたら、それはサイトマスターが html にまとめてくれてるものです(苦笑)
ですんで、このページに関しては、体調治ったトコでちゃんとまとめなおします。
それまでは、暫定版ってことで、悪しからず。
あれから、さらに学研 GDBase について調べてみる。
GDBase の売りの一つに各種プラグインによる機能の追加と言うのがある。
で、どんなんがあるんかいな〜と、ダウンロードページを覗いてみると・・・
『学研電子辞典』で検索できるユーザー辞書を作成・編集します。
見出し数無制限の辞書を作成することができます。
CSVテキストファイルからの読み込みなどが可能です。
はぁぁぁぁぁぁっぁぁぁぁぁぁぁっぁぁぁぁぁぁぁぁぁぁぁぁぁxっぁ!????
と、とりあえず落としてみるですよ。これはもしかして・・・。
えーと、細かい説明は抜きにして、まるで C7x0 のユーザ辞書の登録画面のような手順で、なんか GDBase から漢字源と並んで検索出来る独自辞書が作れてしまいました。
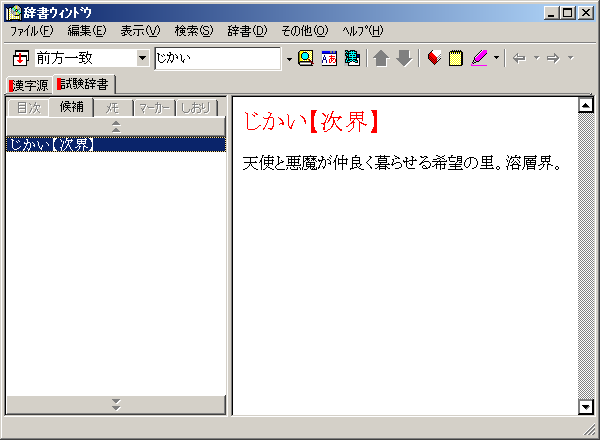
で、次はこいつを 760 に持ってきます。
んと、このユーザ辞書は一応、GDBase 標準の辞書と、区別するためか拡張子が .gdu になってます。(普通は .gdn )ですんで、まず拡張子を .gdn にリネーム。
で、さっきと同じ手順で *.zj_info ファイルを作成してやると・・・。
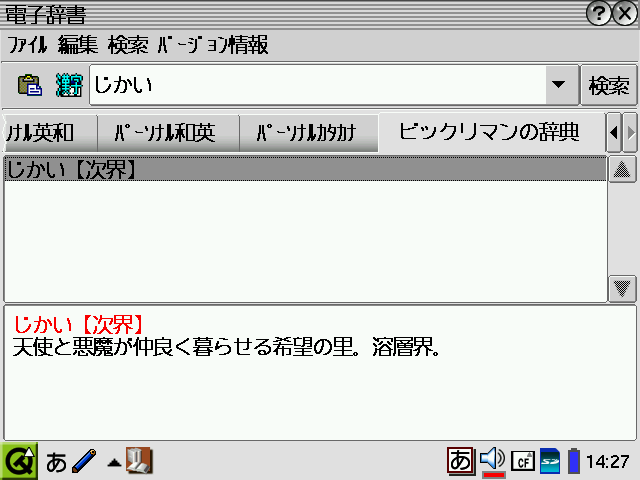
ばっちし。
細かい部分はともかく、実用上の内蔵辞書の解析はこんなもんで十分かと思います。
前述通り、必要なプログラム/ファイルの入手先や、具体的な作成手順等は近日中にちゃんとまとめますんで、今日はこれまで〜。
辞書ファイルは、 *.gdn にリネームしなくても、*.gdu のままで通ることが判明。
さらに、 *.gdu な辞書を追加する場合は、*.zj_info ファイルも不要(大笑)
と、言うことで、ユーザー辞書作成後、ファイルをそのまま任意のフォルダに持ってくるだけで、おっけーだったり。うう、いらん手間かけてもた(^^;)
また、辞書の登録状況は /home/zaurus/Settings/sljisho.conf で、記録・管理されている。
メモリカード等に、辞書をインストールしていて、メディアを抜いた場合や、ターミナルでの操作等、辞書ソフトを通さずに辞書ファイルの本体を動かした場合、起動時にエラーが表示され、検索画面のタブから当該辞書が消える。
その後、動作自体にエラーは表示されないものの、再びメディアを挿入しても、追加した辞書は復活しない。
が、検索画面から辞書が消えても、辞書ソフト本体を通して、辞書の追加と削除を行わない限り、conf ファイルにはしっかりエントリが残ってたりする。
conf ファイルから、エントリを削除するには、直接 conf ファイルを操作するか、元と同じ場所(conf ファイル内で記録されている場所)から、辞書を追加後、削除する必要がある。
以上の点から、辞書ファイルを操作する場合は十分な注意が必要。
実は、このユーティリティ自体は GDBase とは独立したバイナリである。
実行に必要なバイナリは、GDUser.exe、GDULib.dll の2ファイルのみ。
この2ファイルさえ抜き出せば、GDBase 本体の存在しない環境でも、ユーザー辞書の作成は可能。
Web からダウンロード出来るインストールバイナリは、プラグインユーティリティの有無をチェックするので、単体ではインストール不可。
さらに、プラグインユーティリティのインストールは GDBase 本体の有無をチェックするので、結局のところ GDBase 本体(を使用する何らかの学研辞書)が必要となる。通常は。
・・・なんだけど、実はこのインストールバイナリ(gdusrp.exe)、ただの lzh 自己解凍書庫だったり(爆)
と言うことで、自己解凍書庫を扱える解凍ソフト( LHMELT とか)を使えば・・・以下略(苦笑)
基本的に、
CSV と銘打ってはいるが、区切り文字は「,」以外、TAB、セミコロン、スペースの他、任意の区切り文字が指定出来る。
また、文字列の引用符も「"」「'」と指定出来るので、区切り文字を含んだエントリも登録可能。
ここらへん、変換後のプレビューの表示もしてくれたり、結構至れりつくせり。偉いぞ学研(笑)
ライセンス的には、いちお Web ページ上ではフリーウェアになってますが、アーカイブ内に詳細な使用許諾が記されてます。
いちお、ざっと読んだ限りでは、複数のコンピュータでの同時使用や、二次配布等を行わない限りは大丈夫かなーと。
少なくとも、許諾書中で明示されているソースコードや、ファイル形式の中身までの解析は今回手ぇつけてませんし、また条文中で GDBase 本体との関係については触れてませんので、プラグインの単体使用も特に禁じた条文は見つかりません。
強いて、気になる点があるとすれば、複製に関する項目ですが、そもそもパッケージから実行ファイルを取り出す行為自体は、通常のインストールと同じことですからね〜。
とは言え、学研が意図しているインストール方法では無いとは思いますんで、あくまでも自己責任の範疇ってことで。
ま、法律的なところはともかく、本気で使うなら「楽しむ辞典」本体どれか一つくらいは買って、手元に置いとくのが仁義かと思います。
実際、この値段で作成ソフト+辞書データついてくると思えば、破格値だと思いますし(^^;)
以上それぞれが、C760 内蔵辞書のベースになっているものと推測。
で、上記 5 つの辞典に被らず、値段的にも安いものとなると、消去法で漢字源になる。
あと、*.zj_info ファイル中で、漢字源の文字が見えてたんで、通る可能性が高そうだと思えたことも一つ。
さらに、これは買ってから気付いたんだけど、句点コードに JIS、シフトJISに加えて、Unicode も記載されてるのが、何気に便利。
標準の漢和辞典だと、さすがに Unicodeまでは載ってなかったんで、結果オーライ。
でも、この時点で、実は検索ボタンの左にある漢字アイコンで漢和辞典が起動するの知らなかったりして(爆)。それが漢字源選んだ最大の理由と言う話も・・・。
いやぁ、某所で突っ込まれるまで、全然気づいてなかった。いかにマニュアル読んでないかが(^^;)。
ちなみに、辞書の追加が出来る仕様だと言うのも、ざうまにで poex さんが書くまで気づいてなかったりした(苦笑)編注:2003/07/04 の記事
つか、そこで辞書の追加が出来る仕様だと知って、いきなり辞書の解析する気になったと言う話も・・・。
や〜、一人の力なんて、たかが知れてるもんですな・・・(しみじみ)。
・・・この場合、俗に言う、釣られたってやつかもしれんけど(^^;)。